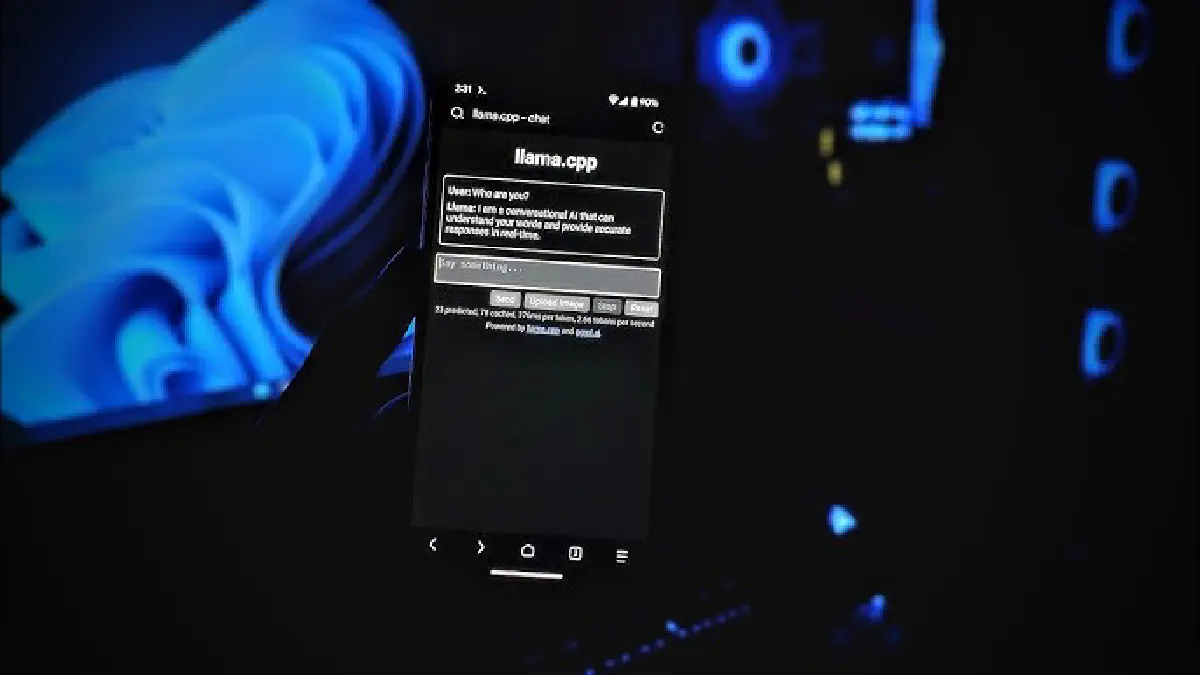
Running a Local LLM on Mobile: Testing PocketPal on iPhone 12#
With the increasing accessibility of large language models (LLMs), running them locally on mobile devices is an exciting prospect. I recently tested PocketPal, a mobile LLM interface, on my iPhone 12, using a distilled 4-bit quantized model. Here’s a breakdown of my experience, covering installation, performance, and overall usability.
Why Run an LLM on Mobile?#
Running an LLM locally on a mobile device comes with several advantages:
- Privacy: No data is sent to external servers.
- Offline Access: Works without an internet connection.
- Lower Cost: Avoids API costs associated with cloud-based models.
What is Quantization?#
Quantization is a technique used to reduce the memory and computational requirements of machine learning models by representing their weights with lower precision numbers. Instead of using 32-bit floating-point numbers, models can be compressed into 8-bit or even 4-bit integers while maintaining reasonable accuracy.
For LLMs on mobile, 4-bit quantization significantly reduces the model size, making it feasible to run on devices with limited resources. However, this compression can lead to:
- Slightly reduced accuracy due to loss of precision.
- Faster inference times, as lower-bit computations require less processing power.
- Lower memory usage, allowing larger models to fit within mobile device constraints.
Setting Up and Running PocketPal on iPhone 12#
1. Download and Install PocketPal#

- Open the App Store and search for PocketPal AI by Asghar Ghorbani.
- Download and install the app.
- Open the app and allow necessary permissions.
2. Adding a Model#

- Navigate to the Models section in the PocketPal app.
- Click the + button to add a new model.
- You will see two options:
- Add from Hugging Face
- Add Local Model
- Select Add from Hugging Face to browse available models.
3. Selecting and Downloading a Model#
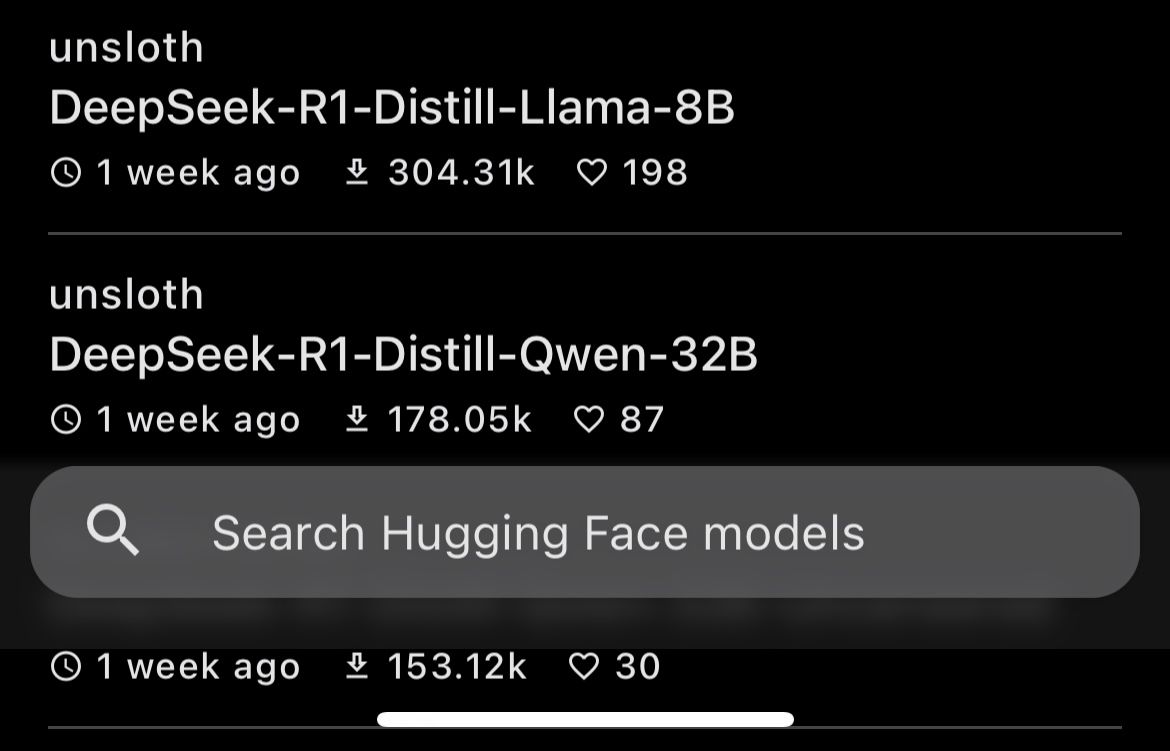
- Search for DeepSeek-R1-Distill-Qwen-1.5B-Q4_0.
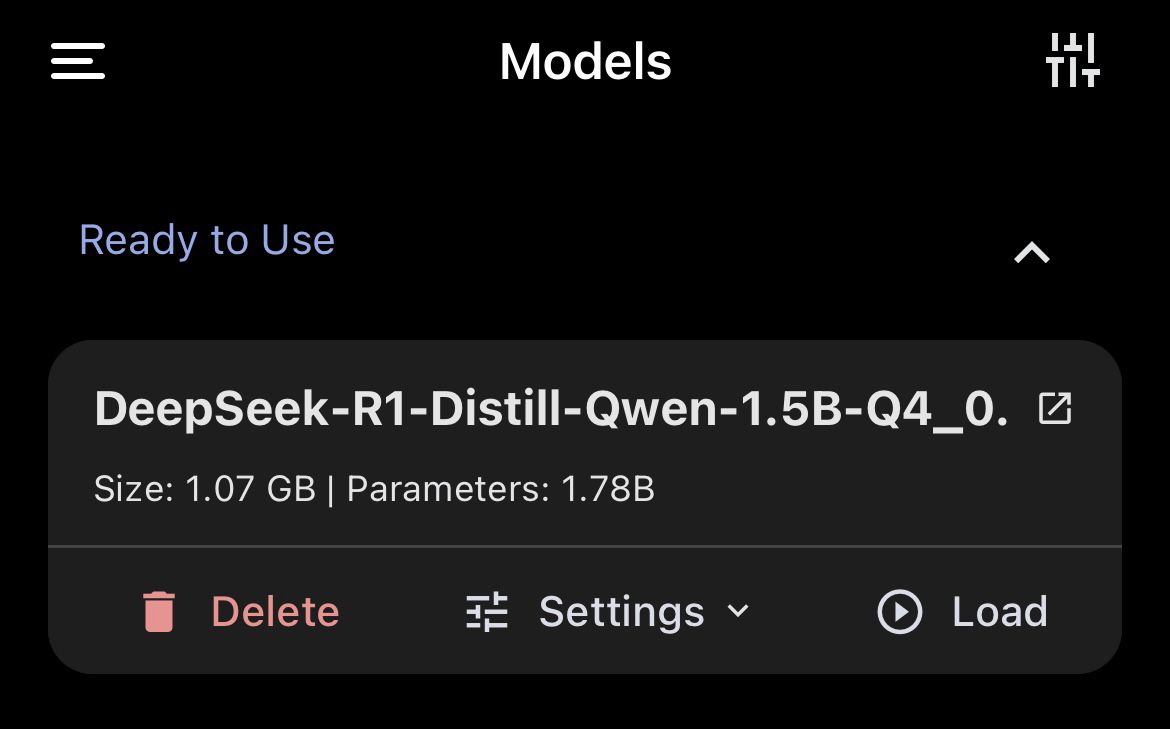
- Select the model and start downloading it (size: 1.06GB, 1.78B parameters).
- Once downloaded, the model will appear under the Ready to Use section.
4. Running Benchmarks#
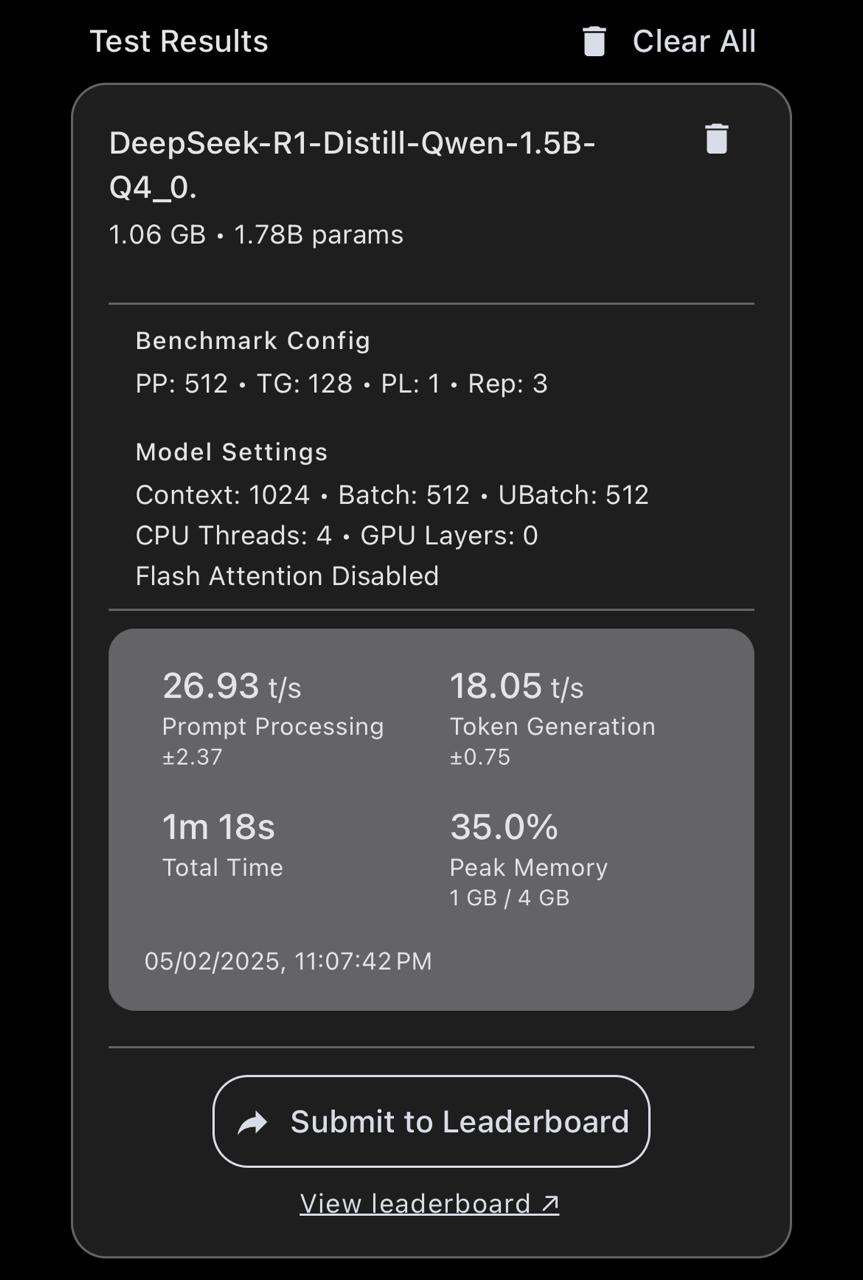
- Model Size: 1.06 GB with 1.78 billion parameters.
- Benchmark Configuration:
- Prompt Processing: 512
- Token Generation: 128
- Pipeline Length: 1
- Repetitions: 3
- Model Settings:
- Context Length: 1024 tokens
- Batch Size: 512
- CPU Threads: 4
- GPU Layers: 0 (fully CPU-based execution)
- Flash Attention: Disabled
- Performance Metrics:
- Prompt Processing Speed: 26.93 tokens/sec (±2.37)
- Token Generation Speed: 18.05 tokens/sec (±0.75)
- Total Execution Time: 1 minute 18 seconds
- Peak Memory Usage: 35.0% (1GB / 4GB)
Live Demo: Running PocketPal on iPhone 12#
Watch a live demonstration of PocketPal running a distilled 4-bit quantized model on an iPhone 12:
Image: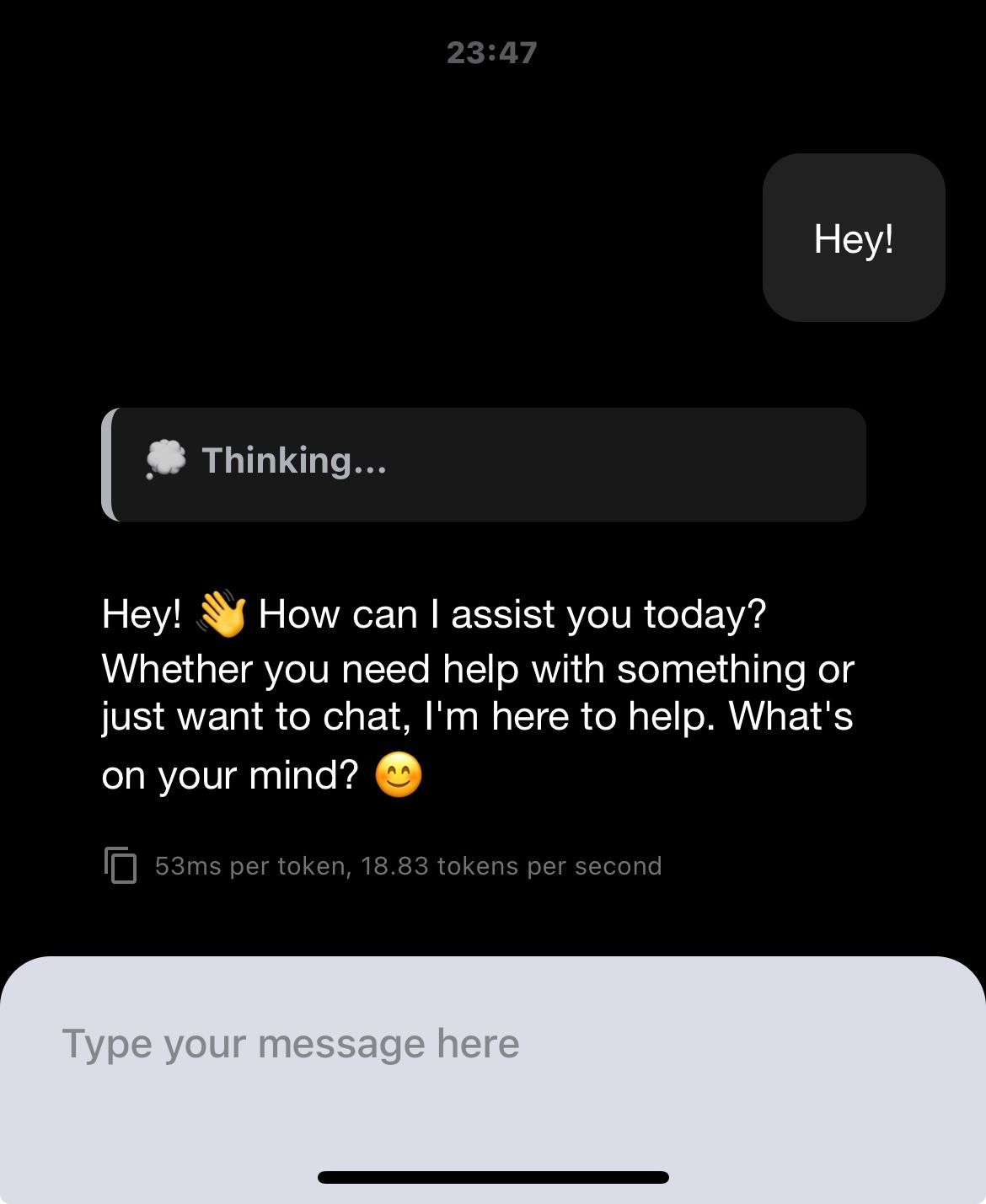
Video demonstration is available here: Video
Analysis of Results#
- Decent Processing Speed: With a distilled 4-bit quantized model, the 18.05 t/s token generation rate is quite reasonable for mobile inference.
- Low Memory Footprint: The 1GB RAM usage means this can run on even mid-range smartphones.
- CPU-Based Execution: Since 0 GPU layers were used, this proves mobile CPUs are capable of running quantized LLMs efficiently.
- Flash Attention Disabled: If supported, enabling it might further optimize speed and reduce lag.
Final Thoughts#
Running an LLM locally on an iPhone 12 with PocketPal is feasible but comes with trade-offs. It’s a promising step toward self-hosted AI assistants, though optimization and hardware improvements will be crucial for broader adoption. If you’re privacy-conscious or need offline AI capabilities, it’s definitely worth exploring!
Future Improvements I’d Like to See:#
- Better memory efficiency to reduce battery drain.
- Enhanced speed for real-time interaction.
- More user-friendly model importing and switching.